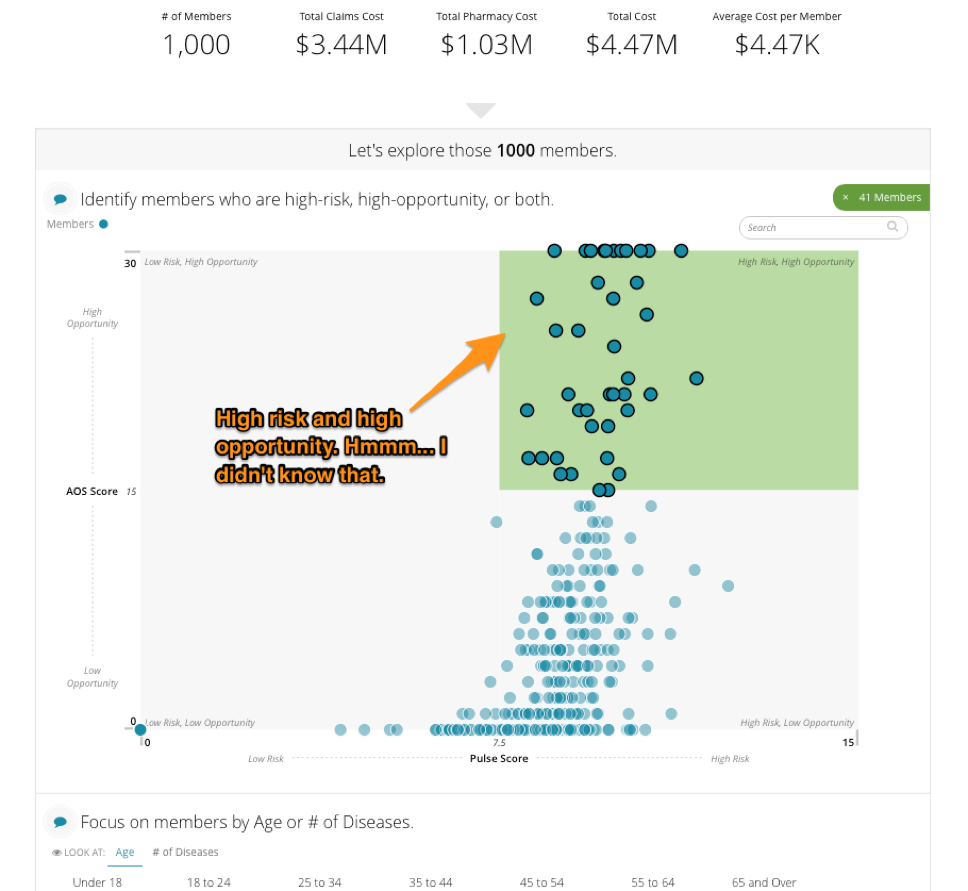
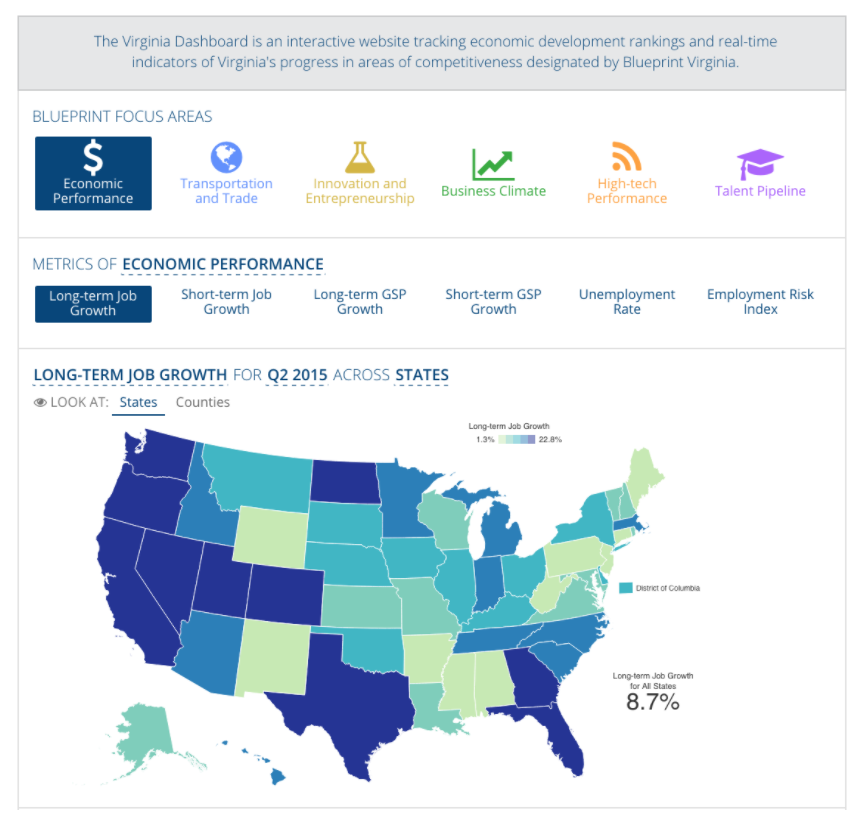
Over the past few weeks, we’ve talked about what it takes to build really great data products. We started with how to go from a blank canvas to design the right data product. This week we want to touch on how to maximize the reach of your data product with Phase 3: Make it available and scalable.

There are two primary areas that facilitate scaling: 1) how the product connects with the target users, and 2) how the technology of the data product enables a higher volume of users and data.
Connect with your target
Just like any other product you might think of, data products need to be used by their target to accomplish their one job. If you followed our Guided Story Design™ process, you’ve already done most of the heavy lifting to connect with your target audience. But there are some post-design considerations that you need to make if you want to maximize how your data product connects with your target.
Before people will use a product, they have to know about it. When you begin the process of telling others about your product, don’t take the “build it and they will come” approach and toss it out there and see what happens. Instead, be intentional about how you introduce folks to your product. Begin with properly-crafted messaging about the problem your product solves. Frame it in a way that they understand how it helps them. Avoid “Hey look at this cool thing I made.” (i.e., what it does for you) and focus on “This application will point you to departments with high staff turnover” (what it does for them). You’ll want to make this message as simple as possible, focusing on the chief problem it solves and leaving discussion of features for later. Realize that if it takes you a paragraph to get someone to understand why they should use it, you’re gonna lose folks before they’ve even tried it out.
Once you’ve connected with your target in a way that makes them want to use the product, you have to make it so that they can actually start using it. Don’t forget that the first time they see the product, they’re going to have to build their own mental framework for how they engage with it; any structure you can put in place to help them with this makes onboarding so much better. Some tricks to lower the barrier to use include gradual reveal, simple introduction videos, and step-by-step guides on how to accomplish common tasks. We love to use new-user tours in our Juicebox apps, but these can also be accomplished through other less automated means (such as onboarding emails, training, or documentation).
In addition to those “push” onboarding ideas, you’ll also want to to consider encouraging “pull” engagement -- allowing your users to connect with you (for user feedback and support) and with other users (to discuss findings and questions). Believe it or not, interpersonal connections about the product will most certainly help them to connect better with the product.
Technology scaling and operations
The second component of scaling the data product is about how well the technology base on which it was composed enables more people to use more data. Because effective scaling is a very complex topic, we’re just going to briefly touch on it here with some scaling questions you’ll want to consider. As you ponder these questions, ask yourself how important each of these are to the success of your product.
Capabilities that make it easier to operate the product on a daily basis:
* Can I bulk add new users? Adding a handful of users by hand is no problem, but if you have to add dozens or hundreds, that’s no fun.
* Can I assign users to group access permissions? If different people need to have restricted access to different things, it may be more efficient to have permission groups to which you assign users so that there are no privacy slip-ups.
* Can I monitor what users are doing and how they’re using the data product? When you know who’s actually using the product you can better tune onboarding efforts.
* Can I load data using automation? Automation reduces error; if data quality is important, this may help.
* Do system resources (e.g., servers, data storage) autoscale to accommodate both growth and idle time? Making sure response times stay reasonable keeps users happier.
Capabilities that report on system health:
* Do I know who’s using the data product (now and in the past)? When you know who’s actually using the product and what they’re doing, you can better respond to questions and feature requests.
* Do I know if data loads ran successfully? Everything works perfectly… until it doesn’t. Then you’ll want to know.
* Can I effectively identify performance bottlenecks? If you know things that impact user experience, you can improve user experience.
* Am I notified when there’s a system issue? You won’t have to spend too much time looking for broken things before you’ll really appreciate smart issue notifications.
Capabilities that enable future improvements:
* Does my technology support my data product’s life cycle? Design → Develop → Production → Upgrade → Retire.
* Can I work on new features and bug fixes without disrupting production? Being able to make changes in a development environment prevents oh so many embarrassing moments.
* Can I reliably deploy a new release without breaking the data product? Don’t miss any pieces and don’t include pieces that don’t belong.
* Can I provide branded versions to my customers that have the same core code? White labeling and customer-specific configurations.
* Can I set up users that have access to different versions of the data product for testing purposes? Giving existing users access to pre-release versions can cure headaches before they happen.
All of these are important things to take into consideration when making your data product available and scalable. It can be a difficult undertaking, but it's not an impossible one. If you have questions or want to know more about the approach we take to build our data products, send us an email at info@juiceanalytics.com or send us a message using the form below.